4 Manipulando Data Frames com dplyr
Entendamos a manipulação de dados como o ato de transformar, reestruturar, limpar, agregar e juntar os dados. Para se ter uma noção da importância dessa fase, alguns estudiosos da área de Ciência de Dados costumam afirmar que 80% do trabalho é encontrar uma boa fonte de dados, limpar e preparar os dados, sendo que os 20% restantes seriam o trabalho de aplicar modelos e realizar alguma análise propriamente dita.
4.1 O Pacote dplyr
O pacote dplyr foi desenvolvido por Hadley Wickham, cientista chefe do RStudio. É uma versão otimizada do pacote plyr. O pacote dplyr não fornece nenhuma funcionalidade “nova” ao R, pois já é feito com base no R, mas simplifica bastante a funcionalidade no R.
Uma contribuição importante do dplyr é que ele fornece uma “gramática” (em particular, verbos) para manipulação
4.2 Gramática do dplyr
Alguns dos principais “verbos” básicos de tablea única fornecidos pelo dplyr são:
-select: retorna um subconjunto das colunas de um data.frames, usando uma notação flexível;
pull(): retire uma única variável;
-filter: extrair um subconjunto de linhas(observações) de um data.frames com base em condições lógicas;
-arrange: reordenar linhas de um data.frames;
-rename: renomear variáveis em um data.frames;
-mutate: adiciona novas variáveis/colunas ou transforme variáveis existentes;
-summarise/summarize: gera estatísticas resumidas de diferentes variáveis no data.frames, possivelmente dentro dos estratos.
4.3 Propriedades das funções do dplyr
As funções têm algumas características comuns:
-1.O primeiro argumento é um data.frames;
-2.Os argumentos subsequentes descrevem o que fazer com o data.frames especificado no primeiro argumento;
-3.O resultado de retorno de uma função é um novo data.frames;
-4.Os data.frames devem devidamente formatados e anotados para que tudo isso seja útil. Em particular, os dados devem estar organizados.
4.4 Instalando o Pacote dplyr
O pacote pode ser instalado a partir do CRAN ou do GitHub usando o pacote devtools com a função install_github(). O repositório GitHub normalmente contém as versões mais atualizadas dos pacotes.
Para instalar a partir do CRAN, bastar executar:
Para instalar a partir do GitHub, execute:
Após a instalação do pacote, carregá-lo com a função library():
Ao carregar o pacote você pode receber alguns avisos, porque há funções no dplyrque têm o mesmo nome que as funções em outros pacotes. Por enquanto pode ignorar os avisos.
4.5 select()
Para melhor apresentar as funcionalidades da função, usaremos um conjunto de dados diários sobre poluição do ar e taxa de mortalidade da cidade de Chicago, nos EUA.
Você pode carregar os dados no R usando a função readRDS():
Este banco de dados encontra no seguinte endereço: http://www.biostat.jhsph.edu/~rpeng/leanpub/rprog/chicago_data.zip e está em um arquivo zipado. Uma das formas para facilitar o processo de descompactação do arquivo pelo R é:
# objeto caracter, endereço do arquivo.
fileURL <- "http://www.biostat.jhsph.edu/~rpeng/leanpub/rprog/chicago_data.zip"
#Esta função pode ser usada para baixar um arquivo da Internet.
download.file(fileURL, destfile = "data/chicago.rds", method = "curl", extra='-L') Descrição do banco: tem 8 colunas e 6940 linhas. Cada linha refere-se a um dia. As colunas são:
- city:
- cidade, neste campo tem apenas “chic” referenciando a cidade de Chicago.
- tmpd:
- temperatura em Fahrenheit.
- dptp:
- temperatura do ponto de orvalho.
- date:
- tempo em dias.
- pm25tmean2:
- partículas médias < 2,5mg por m cúbico (mais perigoso).
- pm10tmean2:
- partículas médias em 2,5^-10 por m cúbico.
- o3tmean2:
- Ozônio em partes por bilhão.
- no2tmean2:
- Medição mediana de dióxido de sulfato.
Umas das formas de ter informações do seu banco de dados é utilizar as seguintes funções dim() e str(). A primeira especifica a dimensão do seu banco e a segunda a estrutura do seu banco de dados.
## [1] 6940 8## 'data.frame': 6940 obs. of 8 variables:
## $ city : chr "chic" "chic" "chic" "chic" ...
## $ tmpd : num 31.5 33 33 29 32 40 34.5 29 26.5 32.5 ...
## $ dptp : num 31.5 29.9 27.4 28.6 28.9 ...
## $ date : Date, format: "1987-01-01" "1987-01-02" ...
## $ pm25tmean2: num NA NA NA NA NA NA NA NA NA NA ...
## $ pm10tmean2: num 34 NA 34.2 47 NA ...
## $ o3tmean2 : num 4.25 3.3 3.33 4.38 4.75 ...
## $ no2tmean2 : num 20 23.2 23.8 30.4 30.3 ...Muitas vezes teremos um data.frames contendo um grande número de dados. Com isso, a função select() permite obter as poucas colunas que você pode precisar.
Suponhamos que desejássemos pegar as 3 primeiras colunas. Há algumas maneiras de fazer isto. Poderíamos, por exemplo, usar o índices númericos. Mas também podemos usar os nomes diretamente.
## [1] "city" "tmpd" "dptp"## city tmpd dptp
## 1 chic 31.5 31.500
## 2 chic 33.0 29.875
## 3 chic 33.0 27.375
## 4 chic 29.0 28.625
## 5 chic 32.0 28.875
## 6 chic 40.0 35.125Normalmente : não pode ser usado com nomes ou sequências de caracteres, mas dentro da função select() pode usá-lo para especificar um intervalo de nomes de variáveis.
Pode omitir variáveis usando a função select() usando o sinal negativo.
## date pm25tmean2 pm10tmean2 o3tmean2 no2tmean2
## 1 1987-01-01 NA 34.00000 4.250000 19.98810
## 2 1987-01-02 NA NA 3.304348 23.19099
## 3 1987-01-03 NA 34.16667 3.333333 23.81548
## 4 1987-01-04 NA 47.00000 4.375000 30.43452
## 5 1987-01-05 NA NA 4.750000 30.33333
## 6 1987-01-06 NA 48.00000 5.833333 25.77233o que indica que estamos incluindo todas as variáveis, exceto as variáveis city até dptp.
O código equivalente ao anterior sem o uso do pacote seria:
## date pm25tmean2 pm10tmean2 o3tmean2 no2tmean2
## 1 1987-01-01 NA 34.00000 4.250000 19.98810
## 2 1987-01-02 NA NA 3.304348 23.19099
## 3 1987-01-03 NA 34.16667 3.333333 23.81548
## 4 1987-01-04 NA 47.00000 4.375000 30.43452
## 5 1987-01-05 NA NA 4.750000 30.33333
## 6 1987-01-06 NA 48.00000 5.833333 25.77233A função de correspondência mathc() retorna um vetor das posições das (primeiras) correspondências de seu primeiro argumento no segundo. De acordo com a Documentação R, a função é equivalente ao operador %in% que indica se uma correspondência foi localizada para o vetor1 no vetor2. O valor do resultado será VERDADEIRO ou FALSO, mas nunca NA. Portanto, o operador %in% pode ser útil em condições if.
Exemplos:
#função math().
v1 <- c("a1","b2","c1","d2")
v2 <- c("g1","x2","d2","e2","f1","a1","c2","b2","a2")
x <- match(v1,v2)
x## [1] 6 8 NA 3#com o operador %in%.
v1 <- c("a1","b2","c1","d2")
v2 <- c("g1","x2","d2","e2","f1","a1","c2","b2","a2")
v1 %in% v2## [1] TRUE TRUE FALSE TRUEA função select() permite uma sintaxe especial que especifica nomes de variáveis com base em padrões. Por exemplo, há várias funções auxiliares que você pode usar:
- 1.
starts_with("abc"): corresponde aos nomes que começam com “abc”;
#Queremos manter todas as variáveis que começam com um "d":
subset3 <- select(chicago, starts_with("d"))
head(subset3)## dptp date
## 1 31.500 1987-01-01
## 2 29.875 1987-01-02
## 3 27.375 1987-01-03
## 4 28.625 1987-01-04
## 5 28.875 1987-01-05
## 6 35.125 1987-01-06- 2.
ends_with("xyz"): corresponde aos nomes que terminam com “xyz”;
## pm25tmean2 pm10tmean2 o3tmean2 no2tmean2
## 1 NA 34.00000 4.250000 19.98810
## 2 NA NA 3.304348 23.19099
## 3 NA 34.16667 3.333333 23.81548
## 4 NA 47.00000 4.375000 30.43452
## 5 NA NA 4.750000 30.33333
## 6 NA 48.00000 5.833333 25.77233- 3.
contains("ijk"): corresponde aos nomes que contêm “ijk”;
## pm25tmean2 pm10tmean2 o3tmean2 no2tmean2
## 1 NA 34.00000 4.250000 19.98810
## 2 NA NA 3.304348 23.19099
## 3 NA 34.16667 3.333333 23.81548
## 4 NA 47.00000 4.375000 30.43452
## 5 NA NA 4.750000 30.33333
## 6 NA 48.00000 5.833333 25.77233- 4.
matches("(.)\\1"): selecionar variáveis que correspondem a uma expressão regular. Esta corresponde a qualquer variável que contenha caracteres repetidos. Você aprenderá mais sobre expressões regulares no capítulo Strings do livro R for data science.
## tmpd pm25tmean2 pm10tmean2 o3tmean2 no2tmean2
## 1 31.5 NA 34.00000 4.250000 19.98810
## 2 33.0 NA NA 3.304348 23.19099
## 3 33.0 NA 34.16667 3.333333 23.81548
## 4 29.0 NA 47.00000 4.375000 30.43452
## 5 32.0 NA NA 4.750000 30.33333
## 6 40.0 NA 48.00000 5.833333 25.77233- 5.
num_range("x", 1:3): Corresponde x1, x2 e x3.
#Criando um objeto df que é um data frame
df <- as.data.frame(matrix(runif(100), nrow = 10))
df <- tbl_df(df[c(3, 4, 7, 1, 9, 8, 5, 2, 6, 10)])
select(df, V4:V6)## # A tibble: 10 x 8
## V4 V7 V1 V9 V8 V5 V2 V6
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 0.851 0.328 0.555 0.168 0.599 0.767 0.0702 0.723
## 2 0.159 0.612 0.401 0.0932 0.270 0.188 0.231 0.957
## 3 0.123 0.674 0.499 0.831 0.264 0.419 0.868 0.329
## 4 0.651 0.207 0.209 0.704 0.881 0.135 0.831 0.952
## 5 0.889 0.499 0.195 0.410 0.496 0.729 0.393 0.570
## 6 0.754 0.483 0.251 0.245 0.973 0.135 0.0957 0.0144
## 7 0.279 0.826 0.963 0.526 0.554 0.384 0.125 0.684
## 8 0.879 0.366 0.890 0.706 0.874 0.590 0.501 0.247
## 9 0.495 0.301 0.301 0.268 0.537 0.608 0.0321 0.999
## 10 0.512 0.226 0.916 0.598 0.640 0.0671 0.0747 0.606## # A tibble: 10 x 3
## V4 V5 V6
## <dbl> <dbl> <dbl>
## 1 0.851 0.767 0.723
## 2 0.159 0.188 0.957
## 3 0.123 0.419 0.329
## 4 0.651 0.135 0.952
## 5 0.889 0.729 0.570
## 6 0.754 0.135 0.0144
## 7 0.279 0.384 0.684
## 8 0.879 0.590 0.247
## 9 0.495 0.608 0.999
## 10 0.512 0.0671 0.606Você também pode usar expressões regulares mais gerais, se necessário. Veja a página de ajuda (?select) para mais detalhes.
select() pode ser usado para renomear variáveis, mas raramente é útil porque descarta todas as variáveis não mencionadas explicitamente. Em vez disso, use rename(), que é uma variante de select() que mantém todas as variáveis que não são mencionadas explicitamente.
Outra opção é usar select() em conjunto com o everything() auxiliar. Isso é útil se você tiver um punhado de variáveis que deseja mover para o início do quadro de dados.
## o3tmean2 no2tmean2 city tmpd dptp date pm25tmean2 pm10tmean2
## 1 4.250000 19.98810 chic 31.5 31.500 1987-01-01 NA 34.00000
## 2 3.304348 23.19099 chic 33.0 29.875 1987-01-02 NA NA
## 3 3.333333 23.81548 chic 33.0 27.375 1987-01-03 NA 34.16667
## 4 4.375000 30.43452 chic 29.0 28.625 1987-01-04 NA 47.00000
## 5 4.750000 30.33333 chic 32.0 28.875 1987-01-05 NA NA
## 6 5.833333 25.77233 chic 40.0 35.125 1987-01-06 NA 48.000004.6 rename()
Para renomear variáveis em uma data.frames em R não é tão prático. E a função rename() foi projetada para facilitar esse processo.
Os nomes das cinco primeiras variáveis do data frame chicago.
## city tmpd dptp date pm25tmean2
## 1 chic 31.5 31.500 1987-01-01 NA
## 2 chic 33.0 29.875 1987-01-02 NA
## 3 chic 33.0 27.375 1987-01-03 NAA coluna dptp deve representar a temperatura do ponto de orvalho e a coluna pm25tmean2 fornece os dados do PM2.5. No entanto, esses nomes são bastante obscuros ou estranhos e provavelmente serão renomeados para algo mais sensato.
## city tmpd Temp_Orv date pm25
## 1 chic 31.5 31.500 1987-01-01 NA
## 2 chic 33.0 29.875 1987-01-02 NA
## 3 chic 33.0 27.375 1987-01-03 NAA sintaxe dentro da rename() função é ter o novo nome no lado esquerdo do = sinal e o nome antigo no lado direito.
4.6.1 Exercícios
4.7 mutate()
Em certas situações é útil adicionar novas colunas/variáveis que são funções de colunas existentes no data frames, ou seja, criar novas variáveis derivadas de variáveis existentes. Esse é o trabalho de mutate(). Esta função adiciona novas colunas no final do seu conjunto de dados. mutate() fornece uma interface limpa para fazer isso. Lembre-se de que, quando você está no RStudio, a maneira mais fácil de ver todas as colunas é View().
Por exemplo, com os dados de poluição do ar, subtraindo a média dos dados. Dessa forma, podemos verificar se o nível de poluição do ar de um determinado dia é maior ou menor que a média (em oposição a observar seu nível absoluto).
Aqui, criamos uma variável pm25difmean que subtrai a média da variável pm25.
## city tmpd Temp_Orv date pm25 pm10tmean2 o3tmean2 no2tmean2
## 1 chic 31.5 31.500 1987-01-01 NA 34.00000 4.250000 19.98810
## 2 chic 33.0 29.875 1987-01-02 NA NA 3.304348 23.19099
## 3 chic 33.0 27.375 1987-01-03 NA 34.16667 3.333333 23.81548
## 4 chic 29.0 28.625 1987-01-04 NA 47.00000 4.375000 30.43452
## 5 chic 32.0 28.875 1987-01-05 NA NA 4.750000 30.33333
## 6 chic 40.0 35.125 1987-01-06 NA 48.00000 5.833333 25.77233
## pm25difmean
## 1 NA
## 2 NA
## 3 NA
## 4 NA
## 5 NA
## 6 NAHá também a função relacionada transmute(), que faz a mesma coisa que, mutate(), mas elimina todas as variáveis não transformadas.
Aqui, desprezamos as variáveis PM10 e ozônio (O3).
chicago %>%
transmute(pm10difmean = pm10tmean2 - mean(pm10tmean2, na.rm = TRUE),
O3difmean = o3tmean2 - mean(o3tmean2, na.rm = TRUE)) %>%
head()## pm10difmean O3difmean
## 1 0.1047939 -15.18551
## 2 NA -16.13117
## 3 0.2714605 -16.10218
## 4 13.1047939 -15.06051
## 5 NA -14.68551
## 6 14.1047939 -13.60218Observe que existem apenas duas colunas no quadro de dados transformados.
Há inúmeras funções que pode ser feita, a propriedade é que a função deva ser vetorizada: ela deve pegar um vetor de valores como entrada, retornar um vetor com o mesmo número de valores que a saída.
4.8 arrange()
A função arrange() é usada para reordenar linhas de um quadro de dados de acordo com uma das variáveis/colunas. Reordenar linhas de um quadro de dados (preservando a ordem correspondente de outras colunas) normalmente é uma tarefa difícil em R. A função simplifica bastante o processo.
Aqui, podemos ordenar as linhas do quadro de dados por data, para que a primeira linha seja a observação mais antiga e a última linha seja a observação mais recente.
## city tmpd Temp_Orv date pm25 pm10tmean2 o3tmean2 no2tmean2
## 1 chic 31.5 31.500 1987-01-01 NA 34.00000 4.250000 19.98810
## 2 chic 33.0 29.875 1987-01-02 NA NA 3.304348 23.19099
## 3 chic 33.0 27.375 1987-01-03 NA 34.16667 3.333333 23.81548
## 4 chic 29.0 28.625 1987-01-04 NA 47.00000 4.375000 30.43452
## 5 chic 32.0 28.875 1987-01-05 NA NA 4.750000 30.33333
## 6 chic 40.0 35.125 1987-01-06 NA 48.00000 5.833333 25.77233
## pm25difmean
## 1 NA
## 2 NA
## 3 NA
## 4 NA
## 5 NA
## 6 NAAgora podemos verificar as primeiras linhas:
## date pm25
## 1 1987-01-01 NA
## 2 1987-01-02 NA
## 3 1987-01-03 NAe as últimas linhas:
## date pm25
## 6935 2005-12-26 8.40000
## 6936 2005-12-27 23.56000
## 6937 2005-12-28 17.75000
## 6938 2005-12-29 7.45000
## 6939 2005-12-30 15.05714
## 6940 2005-12-31 15.00000As colunas também podem ser organizadas em ordem decrescente, usando o operador especial desc().
Observa as três primeiras e as últimas três linhas mostra as datas em ordem decrescente.
## date pm25
## 1 2005-12-31 15.00000
## 2 2005-12-30 15.05714
## 3 2005-12-29 7.45000
## 4 2005-12-28 17.75000
## 5 2005-12-27 23.56000
## 6 2005-12-26 8.40000## date pm25
## 6935 1987-01-06 NA
## 6936 1987-01-05 NA
## 6937 1987-01-04 NA
## 6938 1987-01-03 NA
## 6939 1987-01-02 NA
## 6940 1987-01-01 NA4.9 filter()
A função filter() é usada para extrair subconjuntos de linhas de um data frame. O primeiro argumento é o nome do quadro de dados. O segundo argumento e os argumentos subseqüentes são as expressões que filtram o quadro de dados.
Suponhamos que desejássemos extrair as linhas do banco chicago em que o níveis de PM2,5 sejam maiores que 30, poderíamos fazer
## # A tibble: 6 x 9
## city tmpd Temp_Orv date pm25 pm10tmean2 o3tmean2 no2tmean2
## <chr> <dbl> <dbl> <date> <dbl> <dbl> <dbl> <dbl>
## 1 chic 37 35.2 2005-12-24 30.8 25.2 1.77 32.0
## 2 chic 41 32.6 2005-12-23 32.9 34.5 6.91 29.1
## 3 chic 22 23.3 2005-12-22 36.6 42.5 5.39 33.7
## 4 chic 12 7.7 2005-12-21 37.9 59.5 3.66 34.9
## 5 chic 8 -1.8 2005-12-07 37.8 39 3.92 34.3
## 6 chic 55 49.8 2005-11-08 40 36.5 4.10 27.2
## # ... with 1 more variable: pm25difmean <dbl>Quando você executa essa linha de código, o dplyr executa a operação de filtragem e retorna um novo quadro de dados. As funções dplyr nunca modificam suas entradas; portanto, se você deseja salvar o resultado, precisará usar o operador de atribuição <-.
Para usar a filtragem de maneira eficaz, você precisa saber como selecionar as observações que deseja usando os operadores de comparação. R fornece o conjunto padrão: >, >=, <, <=, !=(não igual), e ==(igual).
Quando você começa com R, o erro mais fácil de cometer é usar = em vez de == testar a igualdade. Quando isso acontece, você recebe um erro informativo:
Há outro problema comum que você pode encontrar ao usar ==: números de ponto flutuante. Esses resultados podem surpreendê-lo!
## [1] FALSE## [1] FALSEOs computadores usam aritmética de precisão finita (eles obviamente não podem armazenar um número infinito de dígitos!). Lembre-se de que todo número que você vê é uma aproximação. Use near():
## [1] TRUE## [1] TRUE4.9.1 Operadores lógicos
Vários argumentos para filter() são combinados com “e”: toda expressão deve ser verdadeira para que uma linha seja incluída na saída. Para outros tipos de combinações, você precisará usar operadores booleanos: & é “e”, | é “ou” e ! é “negação”. A Figura abaixo mostra o conjunto completo de operações booleanas.
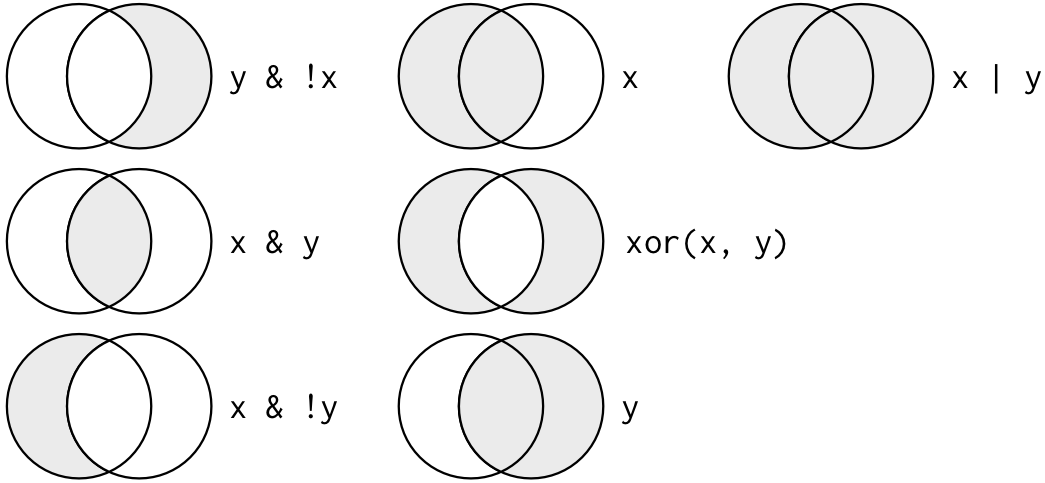
Figure 4.1: Conjunto completo de operações booleanas. x é o círculo do lado esquerdo, y é o círculo do lado direito e a região sombreada mostra quais partes cada operador seleciona.
O código a seguir localiza todas as temperaturas iguais a 30ºF ou 40ºF no banco:
## # A tibble: 136 x 9
## city tmpd Temp_Orv date pm25 pm10tmean2 o3tmean2 no2tmean2
## <chr> <dbl> <dbl> <date> <dbl> <dbl> <dbl> <dbl>
## 1 chic 40 33.6 2005-12-27 23.6 27 4.47 23.5
## 2 chic 30 27.9 2005-12-15 14.4 16.5 4.90 25.4
## 3 chic 30 21.1 2005-11-18 11.7 22.4 4.53 25.0
## 4 chic 40 36.7 2005-10-23 8.5 10 11.6 18.1
## 5 chic 40 25.1 2005-05-02 8 24 17.0 15.4
## 6 chic 30 22.7 2005-03-11 12.0 20.5 23.1 19.9
## 7 chic 30 18.2 2005-02-16 12.8 27.5 19.1 19.9
## 8 chic 30 25 2005-02-03 47.4 53.6 7.27 48.6
## 9 chic 30 26.2 2005-01-30 NA 23 12.4 23.4
## 10 chic 30 27.6 2005-01-09 19.1 17 11.4 19.0
## # ... with 126 more rows, and 1 more variable: pm25difmean <dbl>Às vezes, você pode simplificar um subconjunto complicado lembrando a lei de De Morgan: !(x & y) é o mesmo que !x | !y e !(x | y) é o mesmo que !x & !y. Por exemplo, se você deseja encontrar temperaturas voos que não foram atrasados (na chegada ou na partida) por mais de duas horas, você pode usar um dos dois filtros a seguir:
## # A tibble: 2,156 x 9
## city tmpd Temp_Orv date pm25 pm10tmean2 o3tmean2 no2tmean2
## <chr> <dbl> <dbl> <date> <dbl> <dbl> <dbl> <dbl>
## 1 chic 35 30.1 2005-12-31 15 23.5 2.53 13.2
## 2 chic 36 31 2005-12-30 15.1 19.2 3.03 22.8
## 3 chic 37 34.5 2005-12-28 17.8 27.5 3.26 19.3
## 4 chic 40 33.6 2005-12-27 23.6 27 4.47 23.5
## 5 chic 37 35.2 2005-12-24 30.8 25.2 1.77 32.0
## 6 chic 41 32.6 2005-12-23 32.9 34.5 6.91 29.1
## 7 chic 22 23.3 2005-12-22 36.6 42.5 5.39 33.7
## 8 chic 12 7.7 2005-12-21 37.9 59.5 3.66 34.9
## 9 chic 13 7.7 2005-12-20 25.8 32 3.85 32.9
## 10 chic 5 -0.3 2005-12-19 21.2 21 8.06 31.8
## # ... with 2,146 more rows, and 1 more variable: pm25difmean <dbl>4.10 summarise()
O último verbo-chave é summarise(). Recolhe um quadro de dados em uma única linha:
## # A tibble: 1 x 1
## Média
## <dbl>
## 1 50.3Juntos group_by() e summarise() forneça uma das ferramentas que você mais usará ao trabalhar com dplyr: resumos agrupados.
4.11 group_by()
A função group_by() é usada para gerar estatísticas resumidas do quadro de dados nos estratos definidos por uma variável. Por exemplo, neste conjunto de dados de poluição do ar, convém saber qual é o nível médio anual de PM2.5. Portanto, o estrato é o ano, e isso é algo que podemos derivar da variável date. Em conjunto com a função group_by(), freqüentemente usamos a função summarize() (ou summarise() para algumas partes do mundo).
A operação geral aqui é uma combinação de dividir um quadro de dados em partes separadas definidas por uma variável ou grupo de variáveis ( group_by()) e, em seguida, aplicar uma função de resumo nesses subconjuntos ( summarize()).
A operação geral aqui é uma combinação de dividir um quadro de dados em partes separadas definidas por uma variável ou grupo de variáveis ( group_by()) e, em seguida, aplicar uma função de resumo nesses subconjuntos ( summarize()).
Primeiro, podemos criar uma variável year usando as.POSIXlt() (Funções para manipular objetos de classes “POSIXlt”e “POSIXct”representar datas e horas do calendário).
Agora podemos criar um quadro de dados separado que divide o quadro de dados original por ano.
Por fim, calculamos estatísticas de resumo para cada ano no quadro de dados com a função summarize().
summarize(years, "pm25" = mean(pm25, na.rm = TRUE),
"o3" = max(o3tmean2, na.rm = TRUE),
"no2" = median(no2tmean2, na.rm = TRUE))## # A tibble: 19 x 4
## year pm25 o3 no2
## <dbl> <dbl> <dbl> <dbl>
## 1 1987 NaN 63.0 23.5
## 2 1988 NaN 61.7 24.5
## 3 1989 NaN 59.7 26.1
## 4 1990 NaN 52.2 22.6
## 5 1991 NaN 63.1 21.4
## 6 1992 NaN 50.8 24.8
## 7 1993 NaN 44.3 25.8
## 8 1994 NaN 52.2 28.5
## 9 1995 NaN 66.6 27.3
## 10 1996 NaN 58.4 26.4
## 11 1997 NaN 56.5 25.5
## 12 1998 18.3 50.7 24.6
## 13 1999 18.5 57.5 24.7
## 14 2000 16.9 55.8 23.5
## 15 2001 16.9 51.8 25.1
## 16 2002 15.3 54.9 22.7
## 17 2003 15.2 56.2 24.6
## 18 2004 14.6 44.5 23.4
## 19 2005 16.2 58.8 22.6summarize() devolve uma trama de dados com year primeira coluna, e em seguida, as médias anuais de pm25, o3e no2.